
交叉验证cross validation
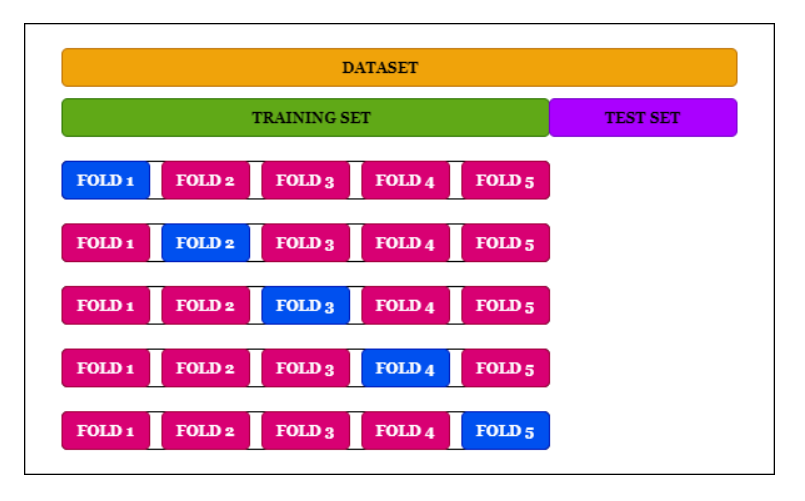
基于tensorflow2.0的交叉验证实现方法。
交叉验证是啥
机器学习模型常常不能很好地对未经过训练的数据进行归纳。有时候表现良好然而有些时候表现糟糕。为了确保模型能在未见数据上表现良好,引出使一种称为K折交叉验证(K-Fold cross-validation)的重新采样技术。
我们训练的时候通常将数据分成三个部分,即训练集、验证集和测试集。但是如果当数据量有限时,将数据集划分为训练集和验证集,可能会导致一些具有有用信息的数据点被排除在训练过程之外,导致模型无法正确地学习数据的分布。这时候交叉验证可以做出一些改进:
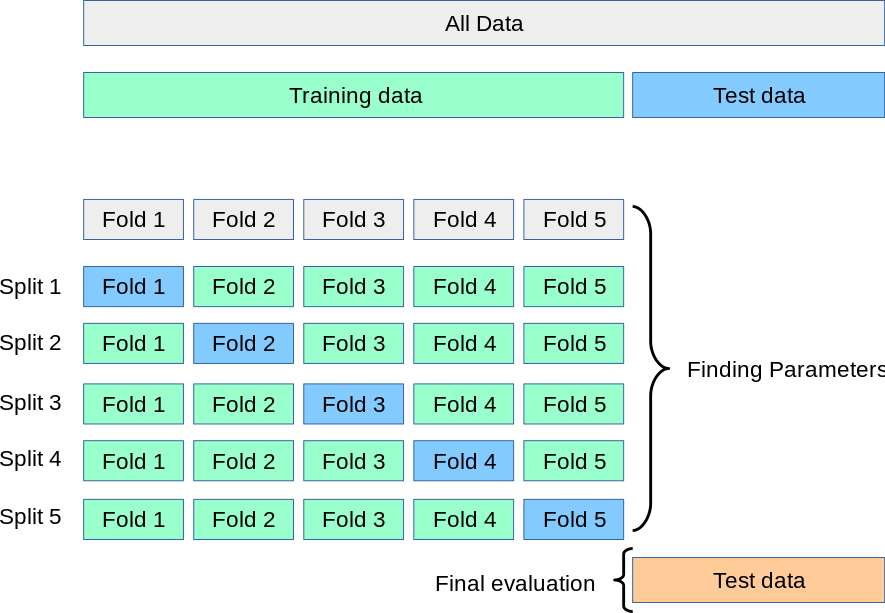
与其他方法相比,K-Fold 给出了一个偏差较小的模型。在k - fold 中,我们有一个参数k。这个参数决定数据集将被划分的折叠数。每一次折叠都有机会出现在训练集(k-1)中,这反过来又确保了数据集中的每一次观察都出现在数据集中,从而使模型能够更好地学习底层数据分布。如上图中k的值为5。
使用的k值一般在5或10之间。k的值不应该太低或太高。如果k的值太低(比如k = 2),我们将得到一个高度偏置的模型。这种情况类似于将数据集拆分为训练集和验证集,因此偏差(bias)较高,方差(variance)较低。如果k的值很大(比如k = n(总体的数量)),那么这种方法称为Leave One Out CV (LOOCV)。在这种情况下,偏差会很低,但方差会很高,模型会过度拟合,导致模型无法在测试集上推广。
另一种方法是在将数据集拆分为k次折叠之前只将数据集洗牌一次,然后再拆分,这样每个类中的观察值的分布在每次折叠中保持不变。测试集也不会在连续的迭代之间重叠。这种方法称为Stratified K-Fold。该方法适用于不平衡数据集。
具体代码实现
这里的编程环境是Tensorflow2.0,要实现交叉验证的核心功能,可以借助sklearn库的KFold和StratifiedKFold类。
from sklearn.model_selection import KFold, StratifiedKFold
具体使用方法可以参考官方wiki:KFold和StratifiedKFold
可以先参考如下文章,前两个具有极大的参考价值:
实现
这是自己自己再综合过程中完成的代码片段:
#coding:utf-8
# Based on tensorflow 2.2
from model_verTF2 import class_net
from data import *
from tensorflow.keras import callbacks
import tensorflow as tf
from sklearn.model_selection import KFold, StratifiedKFold
import os
# enable GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
config = tf.compat.v1.ConfigProto(allow_soft_placement=True)
config.gpu_options.per_process_gpu_memory_fraction = 0.8
tf.compat.v1.keras.backend.set_session(tf.compat.v1.Session(config=config))
# Model confiuration
BATCH_SIZE = 2
EPOCH = 200
FOLD = 9
path = './train_image'
save_dir = './saved_models/'
fold_var = 1
total_data = len(os.listdir(path))
labels = get_all_label(path)
# Define K-fold cross validation
kf = KFold(n_splits=FOLD, shuffle=True, random_state=6)
skf = StratifiedKFold(n_splits=FOLD, random_state=6, shuffle=True)
VALIDATION_ACCURACY = []
VALIDATION_LOSS = []
# Train by cross validation
for train_index, val_index in skf.split(np.zeros(total_data),labels):
train_iter = batch_generator_cross_validation(path=path, index=train_index, batch_size=BATCH_SIZE,train=True)
val_iter = batch_generator_cross_validation(path=path, index=val_index, batch_size=BATCH_SIZE,train=False)
model = class_net()
ckpt = callbacks.ModelCheckpoint(save_dir+get_model_name(fold_var),
monitor='val_accuracy', verbose=1,
save_best_only=True, mode='max')
log = callbacks.CSVLogger(save_dir+'model_log'+str(fold_var)+'.csv')
callbacks_list = [ckpt, log]
print('--------------------------------------------------------')
print(f'Training for fold {fold_var} ...')
history = model.fit(x=train_iter,
steps_per_epoch=len(train_index)/BATCH_SIZE,
epochs=EPOCH,
validation_data=val_iter,
validation_steps=len(val_index)/BATCH_SIZE,
callbacks=callbacks_list)
plot_log(save_dir+'model_log'+str(fold_var)+'.csv')
# load best model to evaluate
model.load_weights("./saved_models/model_"+str(fold_var)+".h5")
results = model.evaluate(x=val_iter, steps=len(val_index)/BATCH_SIZE)
results = dict(zip(model.metrics_names, results))
VALIDATION_ACCURACY.append(results['accuracy'])
VALIDATION_LOSS.append(results['loss'])
tf.keras.backend.clear_session()
fold_var += 1
print('----------------------------------------')
print('Score per fold')
for i in range(0, len(VALIDATION_LOSS)):
print('------------------------------------------')
print(f'> Flod {i+1} - Val_loss:{VALIDATION_LOSS[i]} - Val_accuracy:{VALIDATION_ACCURACY[i]}')
代码段不太完整,留作自己以后检查时调用,待项目完成会放到github上开源,毕竟太辣鸡,只能各种拼凑一下勉强维持一下生活的样子。😱