
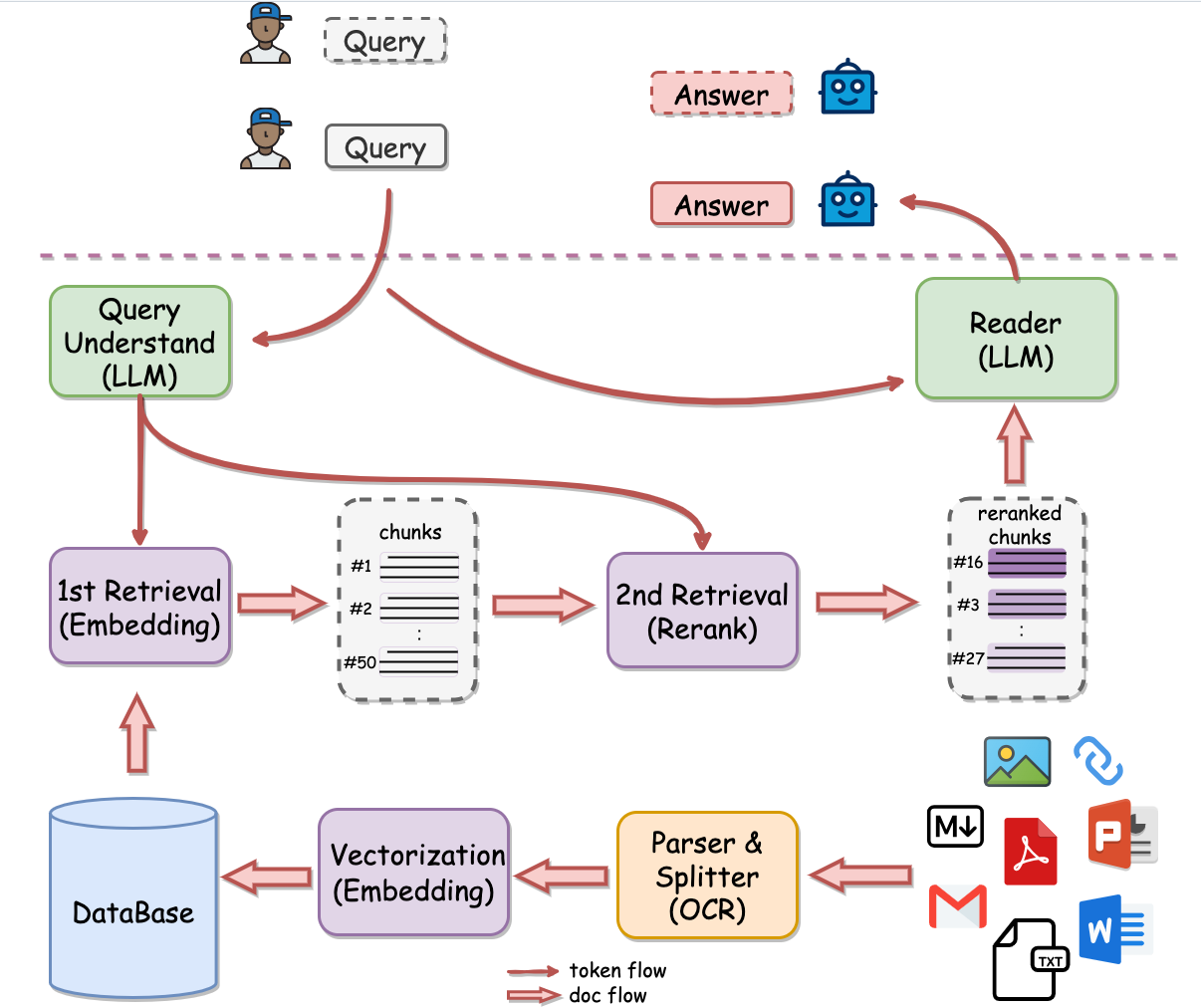
RAG相关知识
RAG 的一些学习参考,主要基于 Lance Martin 的介绍,随时更新。
RAG 定义
RAG(retrieval-augmented-generation)。检索增强生成(RAG)是指对大型语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库。
从技术上讲,RAG是基于知识库检索的提示词增强技术。
根据用户输入的信息在数据库中进行查询,将与查询相关的数据,加入到提示词的上下文中,从而提高模型的回答质量。
这里整理一个基于 langchain 的 RAG 介绍视频教程
GitHub - langchain-ai/rag-from-scratch
RAG From Scratch - YouTube
RAG整体流程和相关技术图如下
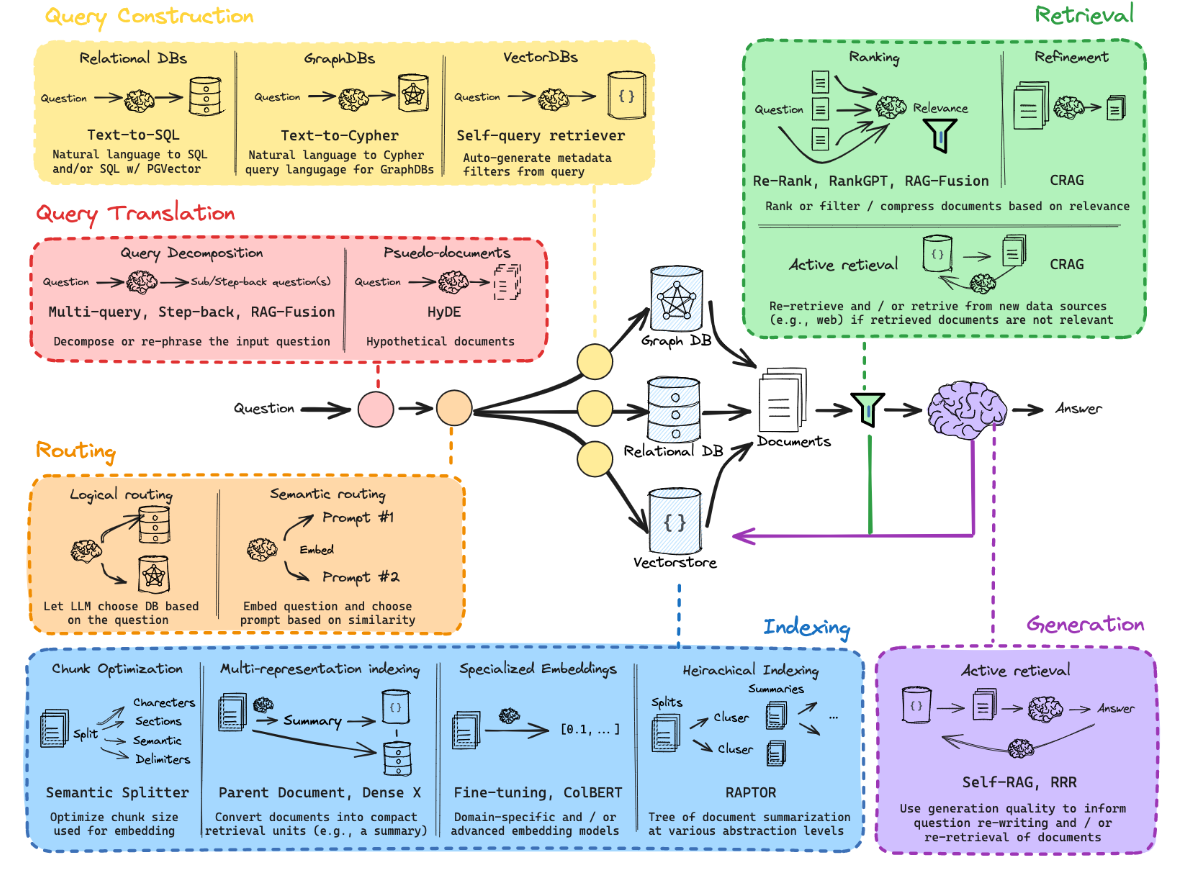
Basic idea
Indexing
通常需要加载数据,分割数据,嵌入操作,这会让后续的 retrieve 操作变得更加方便。
分割(splitting)是因为模型实际上下文窗口是有限的,切分成小块以适应模型。
问题和参考文件都要进行 embedding 操作,转化到向量空间表达(vectorstore)。即使句子没有那么长,embedding 还是会统一到一个固定的向量长度的。
Retrieval
问题和参考文件在进行 index 后,它们共同被转化到更高维度的空间,在此空间中计算相似度以查找和问题相似的参考文件。当然可以寻找很多个(参数中可以定义)相似度高的文件预料作为备选使用。
Generation
将 retrieve 得到的文档放入 LLM 上下文窗口中,进一步得出答案。这一步需要用到 prompt。通常是构建一个 prompt template,将问题和得到的文档按照一定格式输入 LLM ,进行 chatmodel,之后解析为字符串后即可得到答案。
Langchain 中可以轻易的构建 chain,进行一系列操作。使用 invoke 等方法调用 chain
一段简单的流程代码:
import bs4
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
整体例子和理解可以参考 Build a Retrieval Augmented Generation (RAG) App | 🦜️🔗 LangChain
以下为基于 RAG 流程的一些优化的方法,仅作简单解释,自己也不是太懂,随时学习补充。
Query Translation
对于初始输入的问题,可以以某种特定的方法翻译或修改为更好的内容,以改进检索的过程。
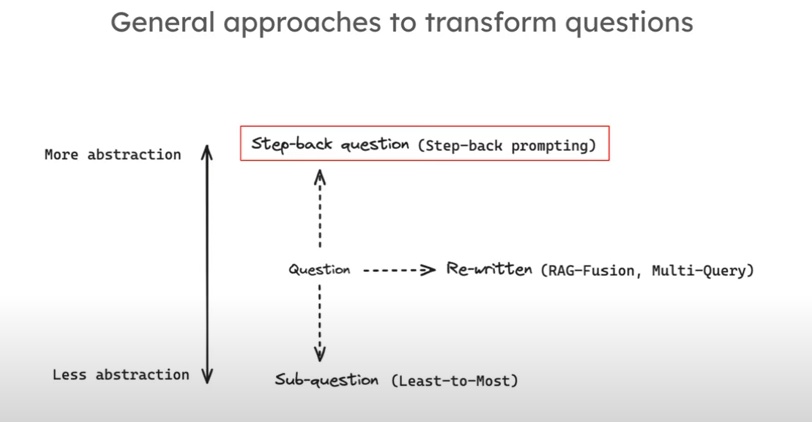
Multi Query
其中一种方法是转换一个问题至很多不同角度的问题,本质上是一种重写(rewritten)。至于如何转化为多个角度的问题,可以直接交给 LLM。
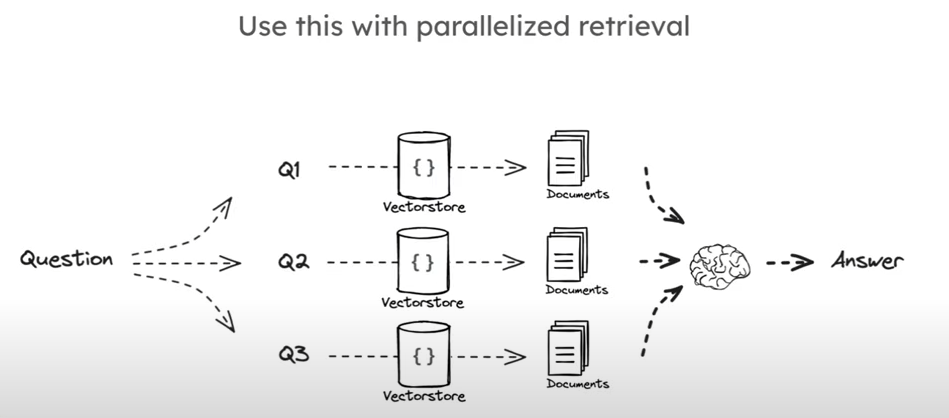
RAG from scratch: Part 5 (Query Translation -- Multi Query) - YouTube
RAG-Fusion
和 multi query 类似,不过在向量化计算相似度之后,进行了一种排序(rank)来检索文档,称为 rank Fusion。
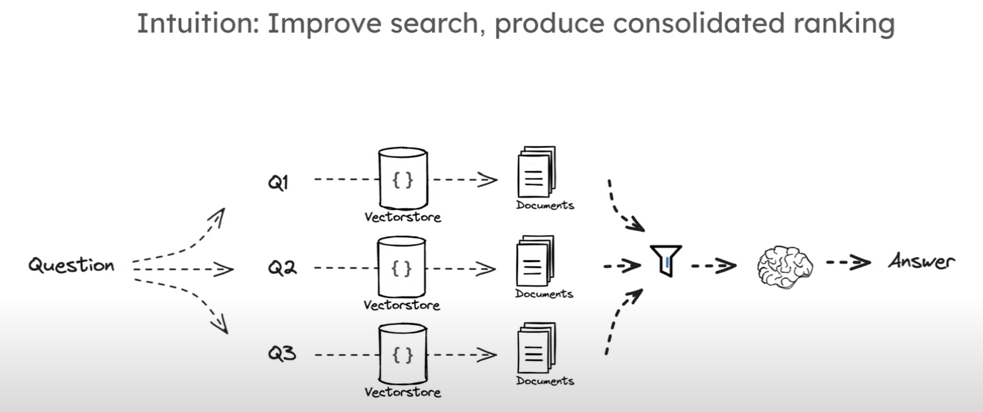
RAG from scratch: Part 6 (Query Translation -- RAG Fusion) - YouTube
Decomposition
Decomposition(Least-to-most prompt context)
将原始的问题分解成多个子问题,并依序解答问题。联合上一个问题得到的答案和这一个问题共同作为预料进行回答。至于如何分解成有嵌套关系的子问题,同样可以直接交给大模型。
IR-CoT: Interleave retrieval with CoT
动态检索以帮助解决子问题,有点 stacking 的味道。
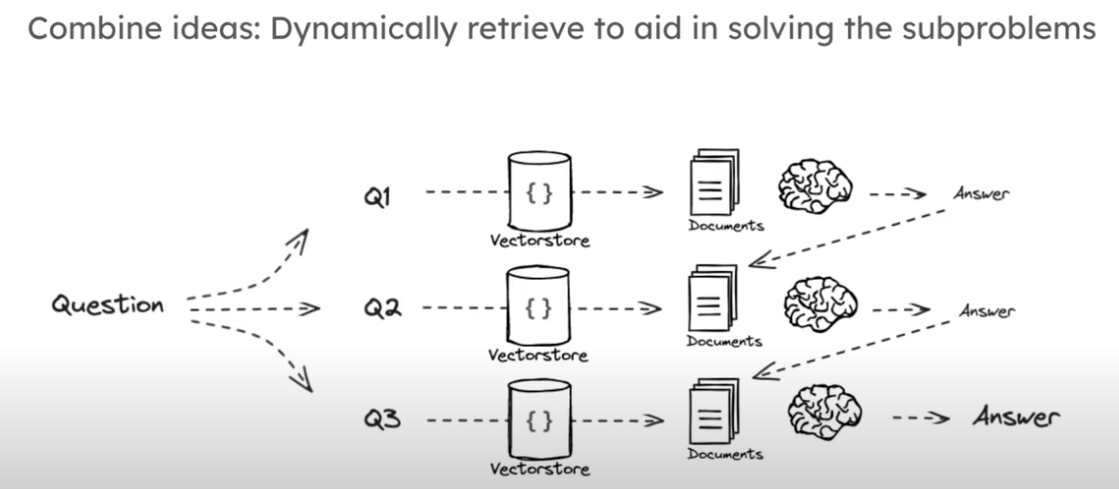
RAG from scratch: Part 7 (Query Translation -- Decomposition) - YouTube
Step-back prompting
通过提问基于该问题的更抽象层面的问题来改善原始问题。
RAG from scratch: Part 8 (Query Translation -- Step Back) - YouTube
HyDE
借助 LLM ,基于问题生成一部分具有参考意义的文档或论文参考,作为假设文档。联合假设文档和自己提供的文档作为语料,让 LLM 回答问题。
RAG from scratch: Part 9 (Query Translation -- HyDE) - YouTube
Routing
Rounting(路由)的作用是假设有很多的数据库,基于得到的问题,能够将问题分配到合适的数据库中进行后续处理。
Logitic routing
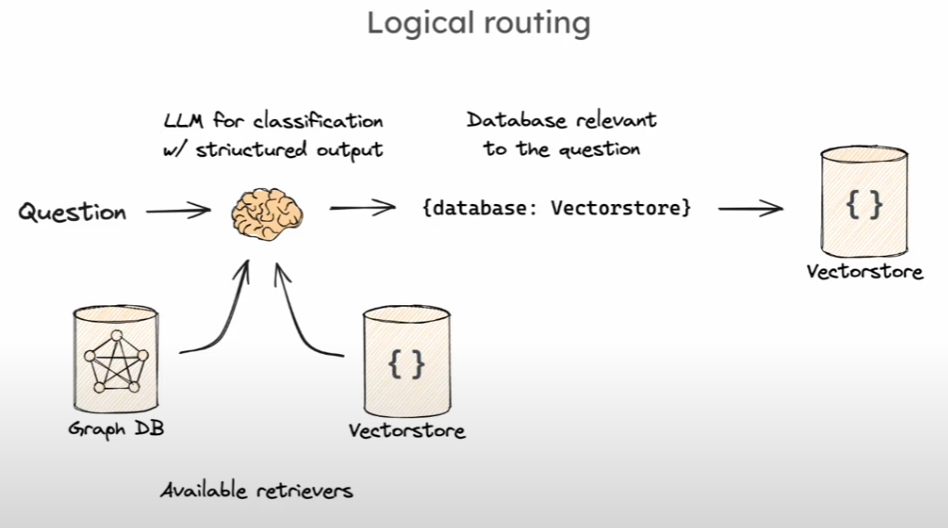
基于不同的库,将输入问题转化为一个结构化对象,对象的输出在不同的几个库中,
RAG from scratch: Part 10 (Routing) - YouTube
Semantic routing
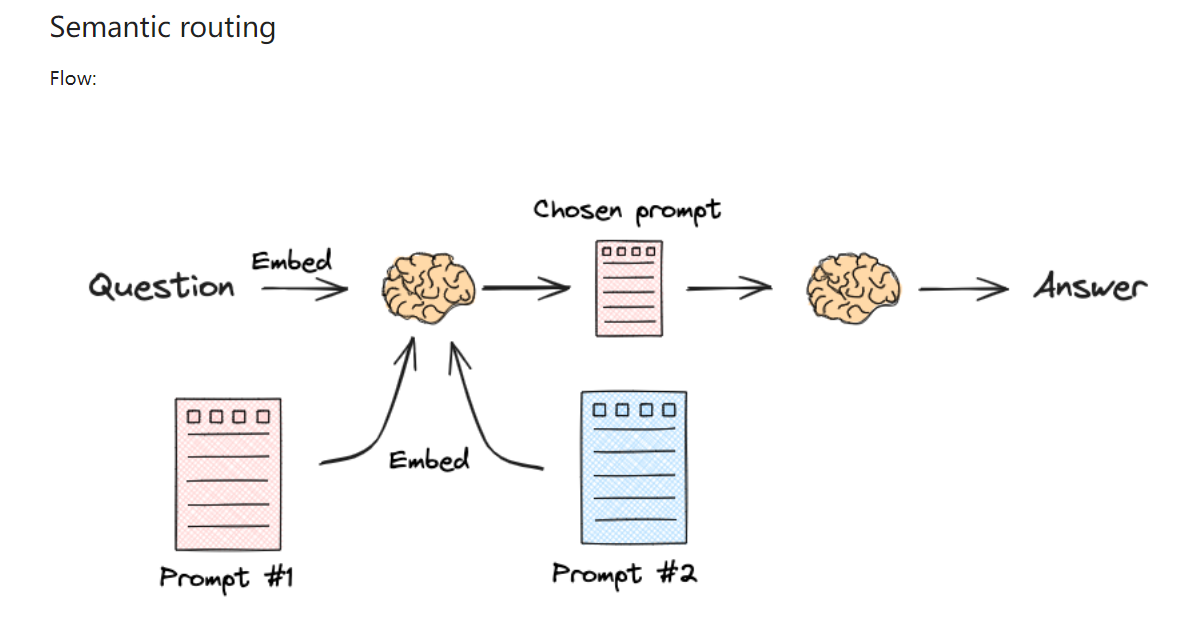
将多个 prompt 嵌入,和问题一起计算相似度,选择相似度高的 prompt 进行后续的问题回答。
这时 LLM 在回答问题的同时,还会返回基于问题的对象。
Query Structuring
目标是将输入的自然语言问题转化为结构化的查询,可以应用于向量存储层面的元数据过滤器。

可以用来作为结构化查询使用
RAG from scratch: Part 11 (Query Structuring) - YouTube
Indexing
Multi -representation
借助 LLM 对原始的文档进行总结并分割,类似于一种蒸馏
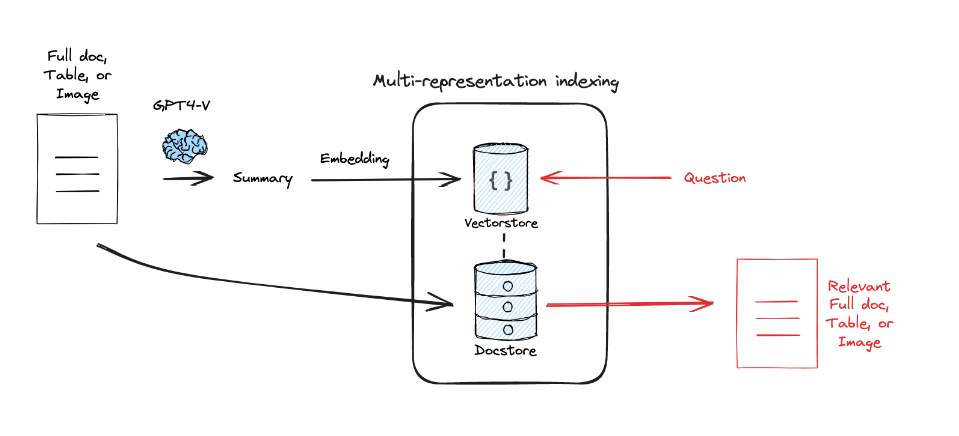
原始文档使用 LLM 总结后放入向量空间,联合原始的文档,进行最终的检索。
RAG from scratch: Part 12 (Multi-Representation Indexing) - YouTube
RAPTOR
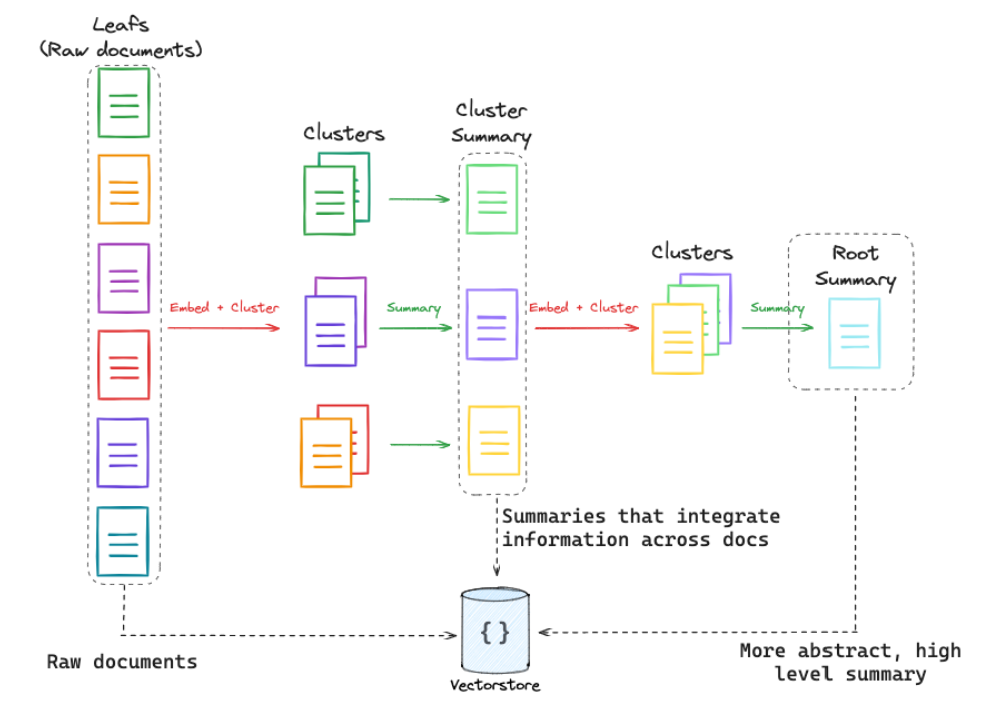
有些信息可能需要来自很多的文件才能得到。这时候可以考虑如下思路,先用聚类的思想,将原始文件分为几块并形成摘要,可以继续抽象到更高层面摘要,逐级进行递归。这样等于是从细致到抽象层面都有非常广的覆盖范围,之后将这些部分共同向量化存储。
RAG From Scratch: Part 13 (RAPTOR) - YouTube
ColBERT
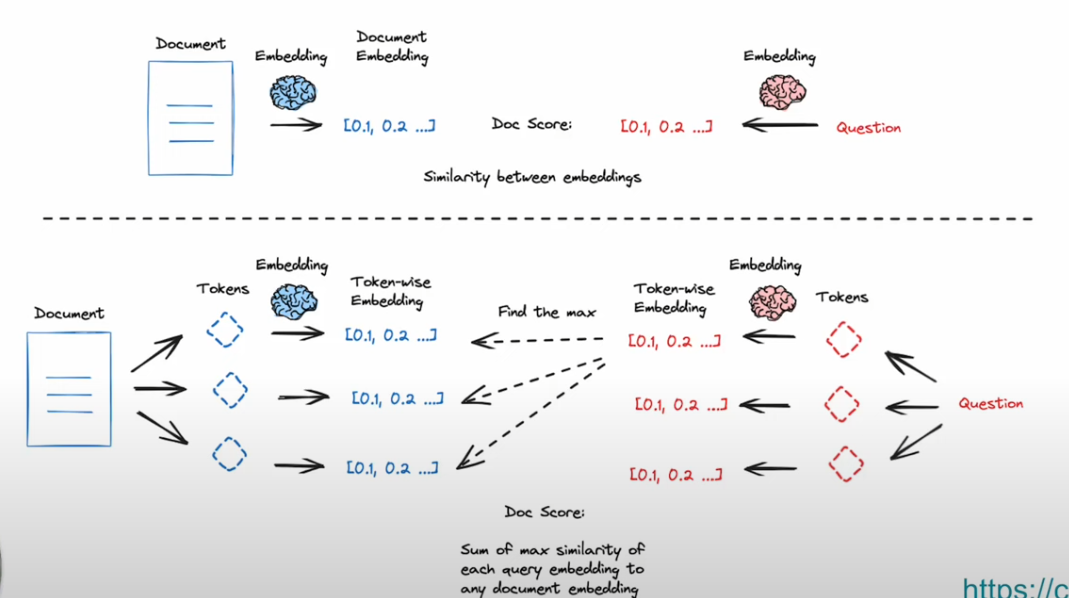
RAG From Scratch: Part 14 (ColBERT) - YouTube
Retrieval
Cohere ReRank
在进行 embedding 后进行搜索时,根据用户问答对语料进行一定程度的排序。
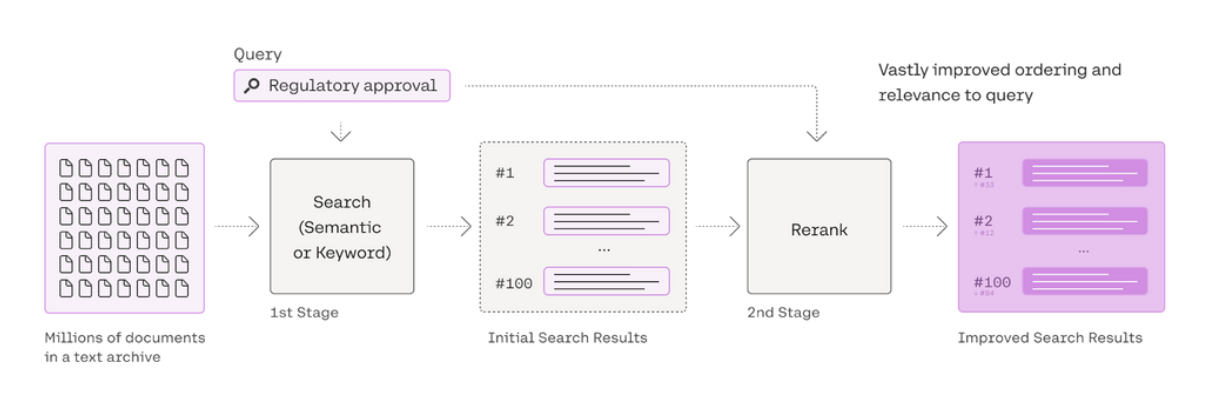
# ReRank 与 Embedding 模型的区别? 如何选择 ReRank 模型?
聊聊QAnything之二阶段检索(粗召回与精排) | 极客之音
GitHub - netease-youdao/QAnything: Question and Answer based on Anything.
Corrective RAG
Building Corrective RAG from scratch with open-source, local LLMs - YouTube langgraph/examples/rag/langgraph_crag_local.ipynb at main · langchain-ai/langgraph · GitHub
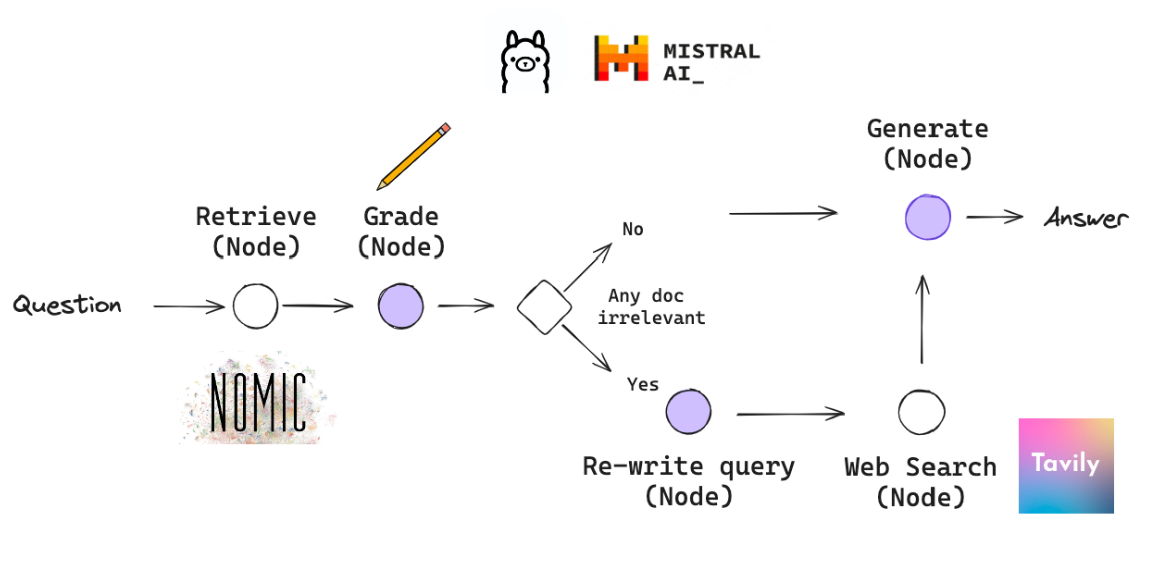
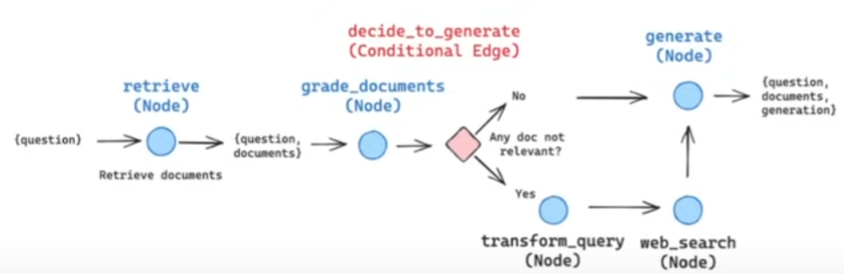
将每一部分抽象为一个节点。借助 langgraph 可以快速构建。
使用 jsonmode,借助 LLM 模型,针对问题对每一段预料其进行结构化的筛选,设定特定字符如 score 再进行后续的操作。例如,score 表示该预料是否和问题相对符合,输出为 yes/no。如果模型判断 score=True,将对应预料保留。如果不是,进行一些 web_search 等操作进行文档补充。最终使用 LLM 进行结果输出。
Embedding models
Embedding models · Ollama Blog
# 如何选择RAG的Embedding模型?
Acge 模型效果比较好
# 下载模型
ollama pull chevalblanc/acge_text_embedding
# 运行模型
from langchain_community.embeddings import OllamaEmbeddings
vectorstore = Chroma.from_documents(documents=splits, embedding=OllamaEmbeddings(model="chevalblanc/acge_text_embedding"))
如何选择RAG的Embedding模型?_哔哩哔哩_bilibili
总结
可以发现,很多技术本身是依赖与 LLM 本身的性能。如果想构建一个性能优异的 RAG 系统,还是得选择一个靠谱的模型。
其他参考
Conversational RAG | 🦜️🔗 LangChain
关于 pydantic 类 Welcome to Pydantic - Pydantic
# RAG共学一:16个问题帮你快速入门RAG