
断点训练的程序
在最近深度学习网络训练的过程中,深刻的体会到了什么叫做「纸上得来终觉浅,绝知此事要躬行」。虽然看了很多的深度学习的训练过程,但实际自己去做还是发现屁都对不上。tensorflow教程为了达到一种「我们的框架很简单,新手很容易上手」的错觉,将很多东西都进行了高级的封装。的确程序是显得很简单,它训练的过程也显得十分顺利,随随便便就可以跑到很高的精度。但是一旦自己上手,用的是自己数据集,瞬间一切变得像难产的婴儿,蛋疼的训练集验证集测试集,每个都让人揪心。
通常训练一个程序的步骤如下:
- 开始初始训练脚本
- 监控损失/准确性
- 注意何时损失/准确性停滞
- 停止训练
- 降低你的学习速度
- 从新的、较低的学习率开始,重新开始训练
在训练过程中,学习率作为一个重要的超参数,不停的调整是非常重要的,然而作为初学者,根本不知道如何去停止,降低学习率然后改变,tensorflow并没有提供那种可以及时暂停调整重新训练的现成程序,仅有的callback只能定义函数去实现学习率的降低(当然也可能是我太菜没发现),需要自己实现。不过经过不懈的搜索,我终于找到了一篇宝藏博客: Keras: Starting, stopping, and resuming training
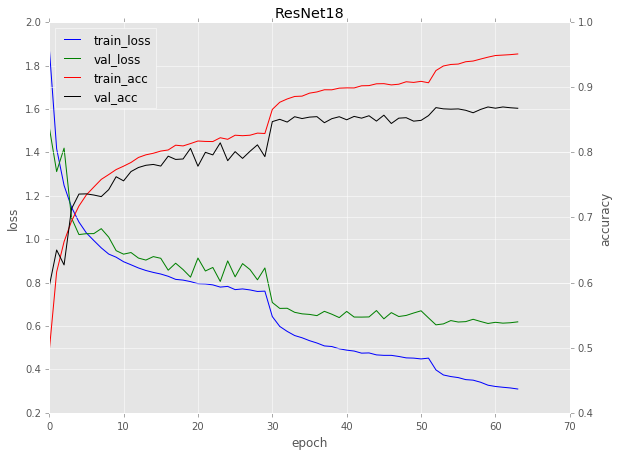
在ResNet18的训练过程中,很明显在30,50epoch那里曲线变化的趋势突然变陡,原因即是在这些特定的epoch训练停止了,学习率降低了一个数量级,然后恢复训练。
在经过几次学习率的减少之后,学习率变得非常小,这反过来又使权重更新变得非常小,因此该模型无法取得任何有意义的进展。
由于学习率低,开始出现过度拟合。 该模型下降到损失情况下损失较小的区域,过度适合于训练数据,而不能推广到验证数据。注意上面有点过拟合,train_loss降低但val_loss有点升高。
降低学习率是在训练过程中提高模型准确性的一种好方法,但需要意识到(1)收益递减点,以及(2)如果训练得不到适当监督就可能过度拟合。
正如博客所说,在训练过程中我们可以通过ctrl+C暂停程序,进而调整优化算法的学习率,后在命令行中继续输入命令得以实现断点训练。
这里贴出文中需要付费得到的重要的callbacks代码:
- epochcheckpoint.py
这个callbacks主要是可以自己定义每隔特定epoch后保存训练的模型
from tensorflow.keras.callbacks import Callback
import os
class EpochCheckpoint(Callback):
def __init__(self, outputPath, every=5, startAt=0):
# call the parent constructor
super(Callback, self).__init__()
# store the base output path for the model, the number of
# epochs that must pass before the model is serialized to
# disk and the current epoch value
self.outputPath = outputPath
self.every = every
self.intEpoch = startAt
def on_epoch_end(self, epoch, logs={}):
# check to see if the model should be serialized to disk
if (self.intEpoch + 1) % self.every == 0:
path = os.path.sep.join([self.outputPath, "epoch_{}.hdf5".format(self.intEpoch + 1)])
self.model.save(path, overwrite=True)
# increment the internal epoch counter
self.intEpoch += 1
- trainingmonitor.py
这个callback主要是记录loss,acc和实时画图检测训练状态的作用
from tensorflow.keras.callbacks import BaseLogger
import matplotlib.pyplot as plt
import numpy as np
import json
import os
class TrainingMonitor(BaseLogger):
def __init__(self, figPath, jsonPath=None, startAt=0):
# store the output path for the figure, the path to the JSON
# serialized file, and the starting epoch
super(TrainingMonitor, self).__init__()
self.figPath = figPath
self.jsonPath = jsonPath
self.startAt = startAt
def on_train_begin(self, logs={}):
# initialize the history dictionary
self.H = {}
# if the JSON history path exists, load the training history
if self.jsonPath is not None:
if os.path.exists(self.jsonPath):
self.H = json.loads(open(self.jsonPath).read())
# check to see if a starting epoch was supplied
if self.startAt > 0:
# loop over the entries in the history log and
# trim any entries that are past the starting epoch
for k in self.H.keys():
self.H[k] = self.H[k][:self.startAt]
def on_epoch_end(self, epoch, logs={}):
# loop over the logs and update the loss, accuracy, etc.
# for the entire training process
for (k, v) in logs.items():
l = self.H.get(k, [])
l.append(v)
self.H[k] = l
# check to see if the traning history should be serialized to file
if self.jsonPath is not None:
f = open(self.jsonPath, "w")
f.write(json.dumps(self.H))
f.close()
# ensure at least 2 epochs have passed before plotting (epochs start at
# zero)
if len(self.H["loss"]) > 1:
# plot the training loss and accuracy
N = np.arange(0, len(self.H["loss"]))
plt.style.use("ggplot")
plt.figure()
plt.plot(N, self.H["loss"], label="train_loss")
plt.plot(N, self.H["val_loss"], label="val_loss")
plt.plot(N, self.H["acc"], label="train_acc")
plt.plot(N, self.H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy [Epoch {}]".format(
len(self.H["loss"])))
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
# save the figure
plt.savefig(self.figPath)
plt.close()
不得不说这两个程序真的是宝藏,完美解决了程序的痛点。
搭配上主程序(博客中已给)
- main.py
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.callbacks.epochcheckpoint import EpochCheckpoint
from pyimagesearch.callbacks.trainingmonitor import TrainingMonitor
from pyimagesearch.nn.resnet import ResNet
from sklearn.preprocessing import LabelBinarizer
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import load_model
import tensorflow.keras.backend as K
import numpy as np
import argparse
import cv2
import sys
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--checkpoints", required=True,
help="path to output checkpoint directory")
ap.add_argument("-m", "--model", type=str,
help="path to *specific* model checkpoint to load")
ap.add_argument("-s", "--start-epoch", type=int, default=0,
help="epoch to restart training at")
args = vars(ap.parse_args())
# grab the Fashion MNIST dataset (if this is your first time running
# this the dataset will be automatically downloaded)
print("[INFO] loading Fashion MNIST...")
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
# Fashion MNIST images are 28x28 but the network we will be training
# is expecting 32x32 images
trainX = np.array([cv2.resize(x, (32, 32)) for x in trainX])
testX = np.array([cv2.resize(x, (32, 32)) for x in testX])
# scale data to the range of [0, 1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# reshape the data matrices to include a channel dimension (required
# for training)
trainX = trainX.reshape((trainX.shape[0], 32, 32, 1))
testX = testX.reshape((testX.shape[0], 32, 32, 1))
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# construct the image generator for data augmentation
aug = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1, horizontal_flip=True,
fill_mode="nearest")
# if there is no specific model checkpoint supplied, then initialize
# the network (ResNet-56) and compile the model
if args["model"] is None:
print("[INFO] compiling model...")
opt = SGD(lr=1e-1)
model = ResNet.build(32, 32, 1, 10, (9, 9, 9),
(64, 64, 128, 256), reg=0.0001)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# otherwise, we're using a checkpoint model
else:
# load the checkpoint from disk
print("[INFO] loading {}...".format(args["model"]))
model = load_model(args["model"])
# update the learning rate
print("[INFO] old learning rate: {}".format(
K.get_value(model.optimizer.lr)))
K.set_value(model.optimizer.lr, 1e-2)
print("[INFO] new learning rate: {}".format(
K.get_value(model.optimizer.lr)))
# build the path to the training plot and training history
plotPath = os.path.sep.join(["output", "resnet_fashion_mnist.png"])
jsonPath = os.path.sep.join(["output", "resnet_fashion_mnist.json"])
# construct the set of callbacks
callbacks = [
EpochCheckpoint(args["checkpoints"], every=5,
startAt=args["start_epoch"]),
TrainingMonitor(plotPath,
jsonPath=jsonPath,
startAt=args["start_epoch"])]
# train the network
print("[INFO] training network...")
model.fit(
x=aug.flow(trainX, trainY, batch_size=128),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // 128,
epochs=80,
callbacks=callbacks,
verbose=1)
训练实例代码:
# 最开始训练
$ python train.py --checkpoints output/checkpoints
# 从40epoch继续训练
$ python train.py --checkpoints output/checkpoints \\
--model output/checkpoints/epoch_40.hdf5 --start-epoch 40
结合以上的代码,可以轻松的暂停程序,调整学习率,在特定的epoch回调,在那个特定点重新进行训练,方便很多。