
大模型框架
本文是书籍 # AI Engineering: Building Applications with Foundation Models 读书笔记的另一部分。
相较与上篇博文聚焦于大模型的调优技术。本文是整体构建一个 AI 系统的框架,但有些知识点较为零散,随时同步笔记更新。
整体 AI 框架
整个 AI 模型架构可以体现为:
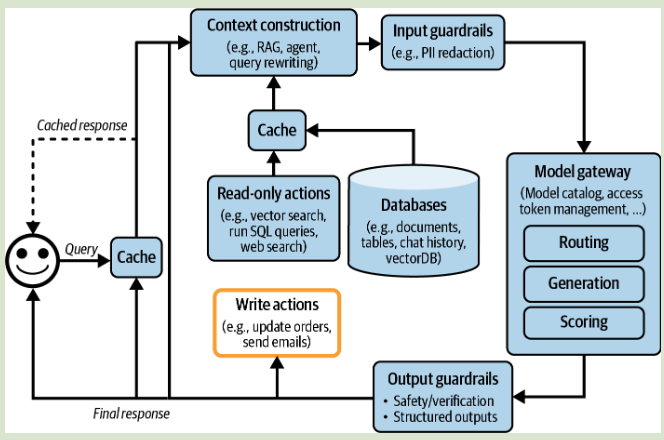
从最基础的 query 和 response 流程开始,逐步增加不同的组件:
- Enhance Context 增强上下文内容:包括 RAG,agent 等相关技术,加入各种数据库等,加强模型回复性能。
- Put in Guardrails 加入防护:包括输入和输出的防护,屏蔽输入的敏感信息,防止输出隐私泄露等问题,过程中要权衡好性能和延迟的关系。
- Add Model Router and Gateway 添加模型路由和网关:针对不同的提问,可以使用不同的模型进行回复。先使用模型(router)进行意图判断和下一步行动的预测,这里的模型可以使用一些基础模型或小的分类器模型,再分发给不同的模型进行后续处理。整个流程可以 routing - retrieval - generation - scoring 去理解。网关主要用于调用不同的模型(整合 API),有一些相关库例如:Portkey’s AI Gateway, MLflow AI Gateway, Wealthsimple’s LLM Gateway, TrueFoundry, Kong, and Cloudflare.
- Reduce Latency with Caches 使用缓存机制减少延迟。包含精确的缓存和语义缓存,用于快速响应。
- Add Agent Patterns 根据具体的需求添加不同的代理模式,由于实现整体的工作流。
整个过程中需要用不同的监控指标去评估各个模块的性能,借助日志记录运行流程,以便快速排查问题。并且收集反馈的过程尽量做到无缝集成,例如 openai 主动询问哪个回复更好。
一些常见的模型框架包括 LangChain, LlamaIndex, Flowise, Langflow,Haystack 等等。
基本模型相关概念
模型规模衡量
大模型现在多以 Transformer 为基础架构,衡量模型大小的关键值如下:
- The models dimension determines the sizes of the key, query, value, and output projection matrices in the transformer block. Q,K,V 值和输出投影矩阵的大小。
- The number of transformer blocks. Transformer 块的数量。
- The dimension of the feedforward layer.
- The vocabulary size.
参数估算:例如,如果模型具有 70 亿个参数,并且每个参数使用 2 个字节(16 位)存储,则我们可以计算出使用此模型进行推断所需的 GPU 内存至少为 140 亿个字节(14 GB)。
但如果模型稀疏,参数估计会有偏差。例如MoE (mixture-of-experts) 技术,MOE 模型分为不同的参数组,每个组都是专家。只有一个专家的子集有效(用于处理每个令牌)。混合 8x7b 是八位专家的混合物,每个专家都有 70 亿个参数。如果没有两个专家共享任何参数,则其应有 8×70 亿个参数。但是,由于某些参数正在共享,它只有 467 亿参数。
模型计算要求的更标准化的单元是 FLOP (floating point operation)
FLOPs 测量一项任务的计算要求,FLOP/s 测量机器的峰值性能。两者写的比较相似,为避免混淆,OpenAI 等会用 FLOP/s-day 去衡量。
1 FLOP/s-day = 60 × 60 × 24 = 86,400 FLOPs
总结,衡量模型的规模:
- Number of parameters
- Number of tokens a model was trained on
- Number of FLOPs
Post-Training 训练后步骤
- Supervised finetuning (SFT):在高质量指令数据上对预训练模型进行微调,以优化对话模型而不是完成模型。
- Preference finetuning:进一步微调模型,以输出符合人类偏好的响应。偏好微调通常通过强化学习 (RL) 完成。
Techniques for preference finetuning include reinforcement learning from human feedback (RLHF) (used by GPT-3.5 and Llama 2), DPO (Direct Preference Optimization) (used by Llama 3), and reinforcement learning from AI feedback (RLAIF) (potentially used by Claude).
关于 RLHF
RLHF 依靠奖励模型(reward model)。给定一对(提示,响应),奖励模型输出了响应效果的分数。独立评估每个样本也被称为点评估(pointwise evaluation)。
奖励模型可以在另一个模型(例如预训练或 SFT 模型)上从头开始训练或微调。
采样 Sampling
模型通过采样过程后进行构建输出。通常输出会取对数 logprobs
有如下多种采样策略:
- Temperature:温度越高,选取最高 logit 值的可能性就越小。温度越低,模型输出值越一致(T=0)。通常建议使用0.7的温度用于创造性用例,因为它可以平衡创造力和可预测性。
- Top-k:为减少输出计算成本,仅选取前 k 个(50~500)logits 上计算 softmax 得出最终结果。
- Top-p:也称为核采样(nucleus sampling)。模型按降序对最可能的下一个值的概率求和,并在总和达到 p 时停止。仅考虑此累积概率内的值。语言模型中 top-p 采样的常见值通常在 0.9 到 0.95 之间。
测试输出效果时,通常使用 logprobs,它可以将相乘概率转化为相加
为了避免偏向短序列,通常对除以序列长度得到平均 logprob。
结构化输出
主要对以下两种情况至关重要:
- 需要结构化输出的任务。最常见类别是语义解析,涉及将自然语言转换为结构化的机器可读格式。
- 下游应用程序使用其输出的任务。在这种情况下,任务本身不需要构造输出,但是由于其他应用程序使用了输出,因此需要通过这些应用程序来解析它们。
评估 AI 系统的方法
评估基础模型有以下难点
- 越高质量的模型越难以评估
- 基础模型的开放性质,无法同传统方法进行评估
- 大多数模型都是黑匣子,不提供详细的模型结构。
接下来列举一些开放性的评估方式
语言模型指标
语言模型的指标,以下 4 个值密切相关。
- cross entropy 交叉熵
用于衡量模型预测的概率分布与真实分布之间的差距,交叉熵越小,说明模型的预测越精准。
H(P, Q) = -\sum_{x} P(x) \log Q(x)
- P(x) 是真实分布(通常是训练数据中的分布)。
- Q(x) 是模型预测的分布。
-
perplexity, PPL 困惑度
困惑度是交叉熵的指数形式: PPL = 2^{H(P, Q)}
同样可以使用自然对数:PPL = e^{H(P, Q)}
模型在预测下一个 token 时的平均不确定性。PPL 越小,模型越确定,越能准确预测下一个 token。 -
BPC (bits-per-character)
BPC=H(P,Q),H (P, Q) 以2 为底的对数计算。
衡量的是编码每个字符所需的平均信息量。如果 BPC = 1.5,则表示每个字符平均需要 1.5 个比特来表示。BPC 越小,说明模型的预测越精准。 -
BPB (bits-per-byte)
与 BPC 类似,字节(byte)而非字符(character)为单位。BPB = 8 \times BPC
| 概念 | 定义 | 单位 | 计算公式 |
|---|---|---|---|
| 交叉熵 (H) | 衡量模型预测的概率分布与真实分布的差距 | bits/token(如果以 2 为底) | -\sum P(x) \log Q(x) |
| 困惑度 (PPL) | 交叉熵的指数形式,表示平均不确定性 | 无单位 | 2^{H(P, Q)} |
| BPC(每字符比特数) | 交叉熵的另一种表示方式(以 2 为底) | bits/character | -\sum P(x) \log _2 Q(x) |
| BPB(每字节比特数) | BPC 的 8 倍,以字节为单位衡量信息量 | bits/byte | 8 \times BPC |
关于 Perplexity 的解释:
- 数据结构化越高,perplexity 越低。
- 词汇量越高,perplexity 越高
- 上下文长度越长,perplexity 越低
相似度测算
需要评估响应与参考数据的相似性,可以使用以下方法:
- 让评估者做出判断
- Extra match 确切匹配,生成与参考是否完全相同。
- Lexical similarity 词汇相似性,生成与参考词汇外观相似度。
使用 N-gram similarity,基于 N 个词汇序列而不是单个单字计算相似度。通常的指标为 BLEU, ROUGE, METEOR++, TER, and CIDEr。 - Semantic similarity 语义相似性,生成与参考含义的相似程度。
需借助 embedding,将文本转化为数值表示,这也是最常见的方法。通常指标为 BERTScore (embeddings are generated by BERT) and MoverScore (embeddings are generated by a mixture of algorithms).
相似度测算是一个重要的评估过程,包含在 AI 系统的多种流程中。
- Retrieval and search 查找类似查询的项目,包含直接和嵌入方法。
- Ranking 排行:基于与查询的相似程度对项目进行排名。
- Clustering 聚类:聚类彼此相似的数据。
- Anomaly detection 异常检测:检测与其余的最小相似的项目。
- Data deduplication 数据删除:删除与其他项目太相似的项目。
借助 AI 进行评估
很多情况下可以借助 AI 进行评估工作,此时 AI 评估的 prompt 需要符合以下标准:
- 模型要执行的任务,例如评估生成的答案与问题之间的相关性。
- 模型应遵循的标准进行评估,例如“你的主要关注点是确定生成的答案是否包含足够的信息,以根据标准答案来回答所提出的问题。”指令越详细,越好。
- 设置评分系统(scoring system),例如:
- 分类,例如好/坏或相关/无关/中性。
- 离散的数值,例如 1 到 5。离散的数值可以被视为分类的特殊情况,其中每个类具有数值解释而不是语义解释。
- 连续数值,例如 0 到 1 之间。评估相似度可以用到。

AI 评估的不足之处:
- Inconsistency 不一致性。
- Criteria ambiguity 标准歧义。不同工具模型的评分系统和定义是不统一的。因此如果无法看到对应的 prompt 不要去轻信 AI 评估
- Increased costs and latency 增加成本和延迟。实际上可以使用与被评判模型性能较低的模型用作评判,因为判断比生成更加简单。
- Biases of AI AI 判断有偏差。很多 AI 会倾向于第一个答案,而人类更会倾向于最后一个答案。有些时候也会偏向于更长的答案,尽管很多时候表达结果是冗余的。
常用的 AI 评估方法:
- Reward model 奖励模型
- Reference-based judge 基于参考的评估。基于正常的参考评估其相似性。
- Preference model 偏好模型。给定 prompt 和多个不同的回答结果,判断哪个回答更加符合用户的偏好。
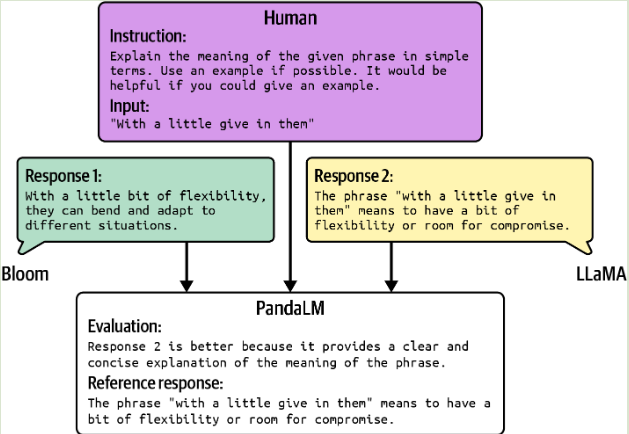
AI 基础模型最终目标是为了下游的应用服务。
评估 AI 系统
具体的实践过程可以如下参考
评估标准
评估 AI 系统可以从以下几方面进行评估:
- domain-specific capability 特定领域的能力
- 是否有在目标领域中实现该功能的能力。
- generation capability 生成能力
- Factual consistency 事实一致性,包括上下文内容的一致和全局知识一致,注意幻觉的产生。同时注意 Knowledge-augmented verification 即知识调查的验证能力。其验证能力可拆解为如下四个步骤:
- 使用 AI 将回答分为单个语句。
- 修改每个语句使其独立(消除上下文的指代与歧义)
- 对于每个语句进行检索操作(内部 or 外部开放 API 检索)
- 借助 AI 确定语句与检索内容是否一致。
- 事实一致性是针对 RAG 系统的关键评估标准。
- Factual consistency 事实一致性,包括上下文内容的一致和全局知识一致,注意幻觉的产生。同时注意 Knowledge-augmented verification 即知识调查的验证能力。其验证能力可拆解为如下四个步骤:
- instruction-following capability 遵循指导能力
- 按照要求进行输出是很重要的能力。不同基准测试有着不同的标准,常见的有 IFEval and INFOBench
- Google 基准 IFEVAL(Instruction-Following Evaluation)的重点是该模型是否可以按照预期格式产生输出。
- Infobench,对跟随指令的含义有更广泛的看法。除了评估模型遵循 IFEVAL 这样的预期格式的能力外,InfoBench 还评估了模型遵循内容限制的能力
- Roleplaying 角色扮演,扮演虚构假定的角色完成对应任务。评估角色扮演能力的基准包括 RoleLLM (Wang et al., 2023) 和 CharacterEval (Tu et al., 2024)
- 按照要求进行输出是很重要的能力。不同基准测试有着不同的标准,常见的有 IFEval and INFOBench
- cost and latency 成本和延迟
- 评估模型时,重要的是平衡质量,延迟和成本三个方面。
模型选择
选择一个合适的模型至关重要,模型可以分为硬属性(模型无法更改的部分,例如使用许可,训练数据,模型大小等)和软属性(可以自我更改的部分,例如准确率,模型毒性,事实一致性等)
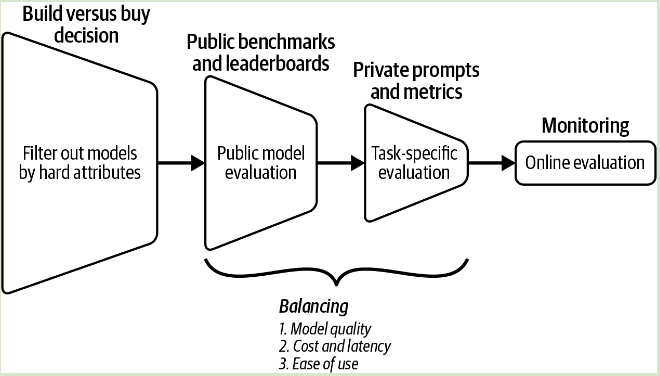
模型选择评估可包含如下 4 个步骤:
- 根据硬属性过滤出不合适的模型。
- 使用公开可用的信息,例如,基准性能和排行榜排名,缩小尝试,寻找合适模型,平衡不同的目标。
- 使用自己的 pipeline 进行评估,找到最佳模型。
- 不断监视生产中的模型以检测故障并收集反馈以改善应用程序。
关于使用自托管模型还是 API,可以从如下几点考虑:
- Data privacy 数据隐私
- Data lineage and copyright 数据来源和版权
- Performance 性能表现
- functionality 功能,例如 Scalability,功能调用,结构化输出,输出保护等等。
- costs API 成本
- control, access, and transparency 可控制程度和透明度
- on-device deployment 设备部署问题
公开的模型基准榜
Huggingface 排行榜 Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard
如何设计评估 pipeline
遵循以下内容:
- Evaluate All Components in a System 评估系统中所有的组件。独立判断出各个组件的功能性,保证都能在要求中运行。
- Create an Evaluation Guideline 创建评估指南
- 定义评估标准(相关性,事实一致性,安全情况等等)。
- 创建带有具体示例的评分系统。
- 与真实世界的具体业务相互联系。
- Define Evaluation Methods and Data 评估方法和数据。选择合适的具体的方法和对应的数据进行效果评估。针对模型性能,OpenAI 的经验是,对于分数差的每 3 倍降低,所需的样本数量增加 10 倍。
数据集工程
在数据规划上,数据需遵循以下标准:
- 数值质量:少量的高质量数据可以胜过大量嘈杂的数据。数据一般要求以下特征:相关,与任务要求保持一致,持续性高,格式统一正确,数据不重复和合规。
- 数据覆盖范围:数据尽可能广泛,例如能够理解错别字,那么训练数据就应该包含错别字。
- 数据数量:从小数据集开始测试,预估需要多少数据。如果有少量数据,则可能需要在更高级的模型上使用 PEFT。如果有大量数据,可以使用较小的模型进行完整的 finetuning。
数据增强与合成
对于有限的数据,可以用同义词的词典找到类似的单词,也可以通过在单词嵌入空间中彼此接近嵌入的词来找到类似的单词。数据合成的步骤可以使用 AI 模型实现,并可以像真实数据一样使用启发式方法过滤
数据处理
优化数据处理效率的方法:
- 首先对数据进行观察,选择合适的处理顺序以节省时间。
- 批量数据脚本运用到数据之前保持进行充分的测试。
- 所有的数据处理保留原始的副本。
处理过程包括:
- 检查数据:评估其质量,获取相关信息和统计方面数据,是否应符合某种分布等。
- 避免重复数据:重复数据会引发模型的偏见。删除重复数据的方案可以考虑相似度测量等技术。一些删除重复数据的项目 dupeGuru, Dedupe, datasketch, TextDistance, TheFuzz, and deduplicate-text-datasets.
- 清洗数据:制定流程,保持模型的安全性。
- 格式化数据:保持数据统一的格式化输入用于后续训练等操作。